There is so much data available on the internet - even if it isn't always in an analysis friendly format. The results of any modern sports tournament are hosted somewhere. Countless blog posts and movie reviews are available to the public free of charge. This information can be extracted programmatically allowing researchers to build large datasets without tedious manual input.
BeautifulSoup is a web scraper Python library that makes it a snap to request HTML pages and parse the information on them. With a few short loops, information hosted on a web page is organized into a luxurious CSV or JSON file. Scraping a set of web pages has 2 parts: how do I extract the information on an individual page and how do I get the set of pages to parse from?
It comes down to pattern recognition and using the element inspector. The user score could have its own div. The URLs of each page may only differ by a date or city name. Better yet, there could be a page that contains the URL for every episode of a TV series. Each situation is going to be different so let's take a look at a simple use case.
Collecting a list of National Parks
For this example I am going to scrape the National Park Service website to create a dictionary of all listed parks and their individual URLs. I start by extracting the information from a single page with the assumption that most of the pages will have the same format.
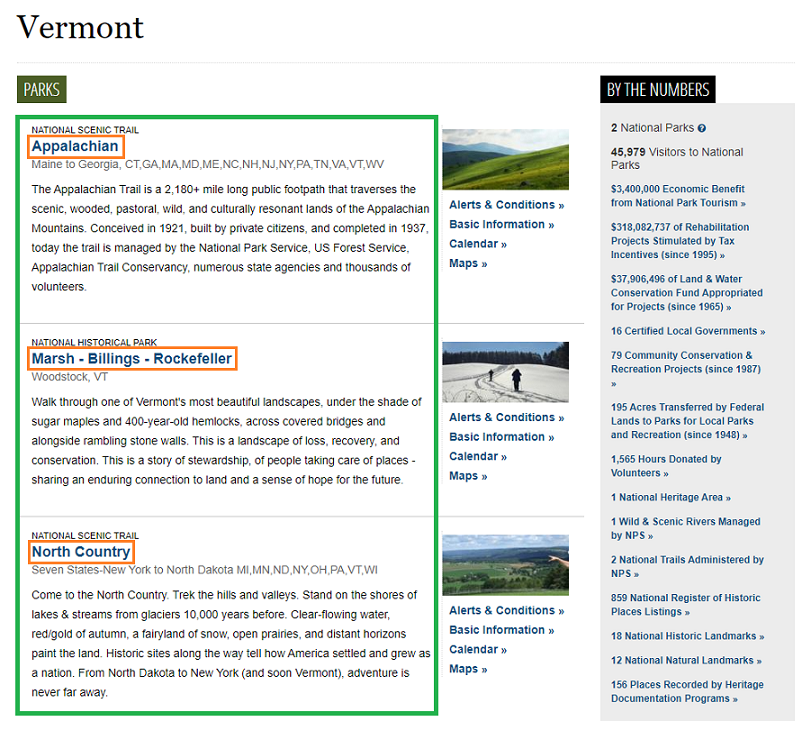
The orange boxes show the indvidual entries and the green box is a container that holds all of them. Now its time to use the page inspector to find a way for BeautifulSoup to parse these locations. The green box has id="parkListResultsArea". The orange boxes are links surrounded by h3 tags within the parkListResultsArea.
Extract parks from Vermont's page
from bs4 import BeautifulSoup
import requests
url = "https://www.nps.gov/state/vt/index.htm"
soup = BeautifulSoup(requests.get(url).content)
vermont = soup.find(id = "parkListResultsArea")
parks = vermont.find_all('h3')
for park in parks:
link = park.find('a')
print(link.get_text())
Output
Appalachian
Marsh - Billings - Rockefeller
North Country
The scraper returns the desired information from a single page. Now let's expand the code to retrieve information from multiple pages. I created a function that takes a url and executes the scraping logic. With a simple loop I can call the function for multiple states. I also added a function that takes the information from each park and transforms it into a dictionary.
Helper Functions
# Retrieve all parks from a state's page
def parse_state(url):
soup = BeautifulSoup(requests.get(url).content)
state = soup.find(id = "parkListResultsArea")
parks = state.find_all('h3')
return parks
# Transfrom a BeautifulSoup tag to a dictionary of park information
def parse_park(park, state):
tag = park.find('a')
url = tag['href']
name = tag.get_text()
park_dict = {"Name": name, "State": state, "URL": url}
return park_dict
Main
# Full results container
results = []
url = "https://www.nps.gov/state/PLACEHOLDER/index.htm"
states = ["vt", "de", "wi"]
# For every state in the above list
for state in states:
# Retrieve all parks from the state's page
state_url = url.replace("PLACEHOLDER", state)
state_results = parse_state(state_url)
# For every park in the state's page
for park in state_results:
# Transform the BeautifulSoup tag to a dictionary of park information
park_result = parse_park(park, state)
results.append(park_result)
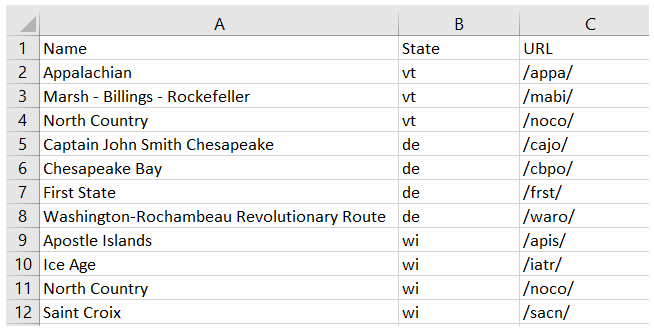
Each state park on the Vermont, Delaware, and Wisconsin pages have been recorded in a dictionary. All such dictionaries are stored in a list called results. This is a format that is easy to transform into a CSV.
Write list of dictionaries to CSV
import csv
with open('export.csv', 'w', encoding='utf-8', newline='') as output_file:
writer = csv.DictWriter(output_file, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
BeautifulSoup is a great tool for pulling information from HTML files. Often, the questions that I want answered need a dataset that hasn't been organized so I should get used to building them myself.